Subscribe. Scale. Succeed.
We’re so confident you’ll love Akkio, we’ve made our service month to month. Ideal for people with commitment issues and ROI desires.
Did you know that there are several different types of classification algorithms? Algorithms are used to crunch massive data sets in order to make predictions. In particular, classification has a huge range of use-cases, from predicting what type of product a customer will buy, to classifying an image or text into a category, to deciding whether or not to pursue a marketing lead.
Given this huge potential, companies large and small are investing heavily in machine learning classification models. In this article, we're going to explain what machine learning and classifiers are, as well as five major types of classification algorithms used in practice today.
Machine learning is the next step in the progression of computing. It involves creating computer programs that can learn without being explicitly programmed. This gives machines “intelligence” so they can improve themselves over time based on input data.
In other words, it’s a way to give computers the ability to make predictions and decisions without having to be told what to do by a human operator. One of the most common use cases for machine learning is in classification: figuring out what type of category something is supposed to be, whether it’s textual data, numerical data, an image, or even an audio snippet.
Classification is a natural language processing task used in machine learning to assign labels to data items. With an input training dataset, classification algorithms can identify categories and classify subsequent data accordingly. So they essentially identify and recognize patterns in the training data and use the findings to find similar patterns in future data.
Most classification models are supervised machine learning problems, since the input data has class labels. However, unlike unsupervised learning, supervised learning models use labeled input variables.
Let's look at an example: Spam detection is a common use of classification. A spam filter looks for patterns in an email and determines whether it should be categorized as spam or not. This works by looking for associated spam characteristics, such as the patterns in images or links, and classifying the rest of the email accordingly.
Billions of people benefit from spam filtering every day. Your email client probably has a spam filter, and the same concept is at play. In fact, your browser likely uses a variation of this algorithm to determine whether or not to render a particular webpage for you to view.
To give another example, financial institutions use classification algorithms to detect fraudulent transactions. By looking for patterns that are associated with fraud, they can automatically flag potential fraudulent activities and prevent them from happening.
There are several different types of classification algorithms, each suited for a different type of data set. Akkio uses a variety of classification algorithms to help our customers get the most out of their data.
Let's look at an example of using Akkio to predict customer churn, which is a popular classification problem.
Say we have a set of training data consisting of customers and their churn rate. We can upload this data to Akkio, which will look at the data to identify patterns or trends that might indicate what to expect for customer churn in the future.

We then select the "Churn" column to build a model, and in seconds, we’ll have a highly accurate churn prediction model. As you can see below, Akkio used a Sparse Neural Network for this dataset.

Finally, you can hit “Add Step” and "Deploy" to deploy in any chosen setting, whether it’s Hubspot, Snowflake, Google Sheets, or thousands of other applications with Zapier. Akkio will then use the model to make predictions on new data, which will be presented in real-time.
While we’ve made a churn prediction above, you could just as easily follow these steps for tasks like sentiment analysis.
Let’s dig deeper into eight types of classification algorithms:
Support Vector Machines (SVM) are robust and effective machine learning algorithms that transform your data into a linear decision space. The algorithm then determines the optimal hyperplane in this linear decision space, which separates your training data into different classes, such as legitimate or spam email.
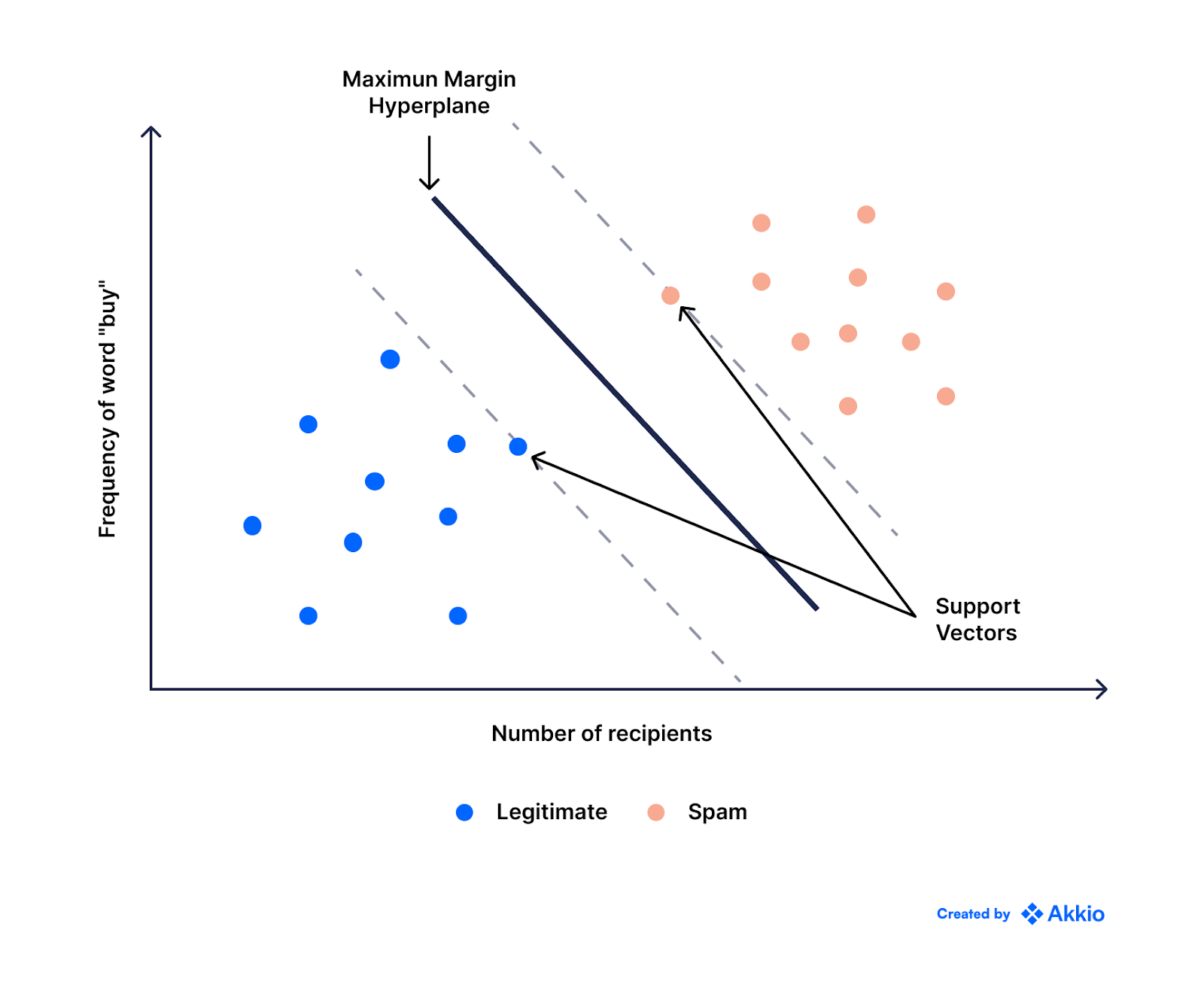
SVM is particularly good at separating similar things. For instance, all the examples in a group might be similar, while some examples in a different group might be very different from each other.
This makes it ideal for classification tasks that can be well classified with a straight line, which, as you can imagine, does not apply to all classification tasks.
The K-nearest neighbors algorithm is one of the most basic classification algorithms. It compares each example of a particular class to all examples of that class by proximity.
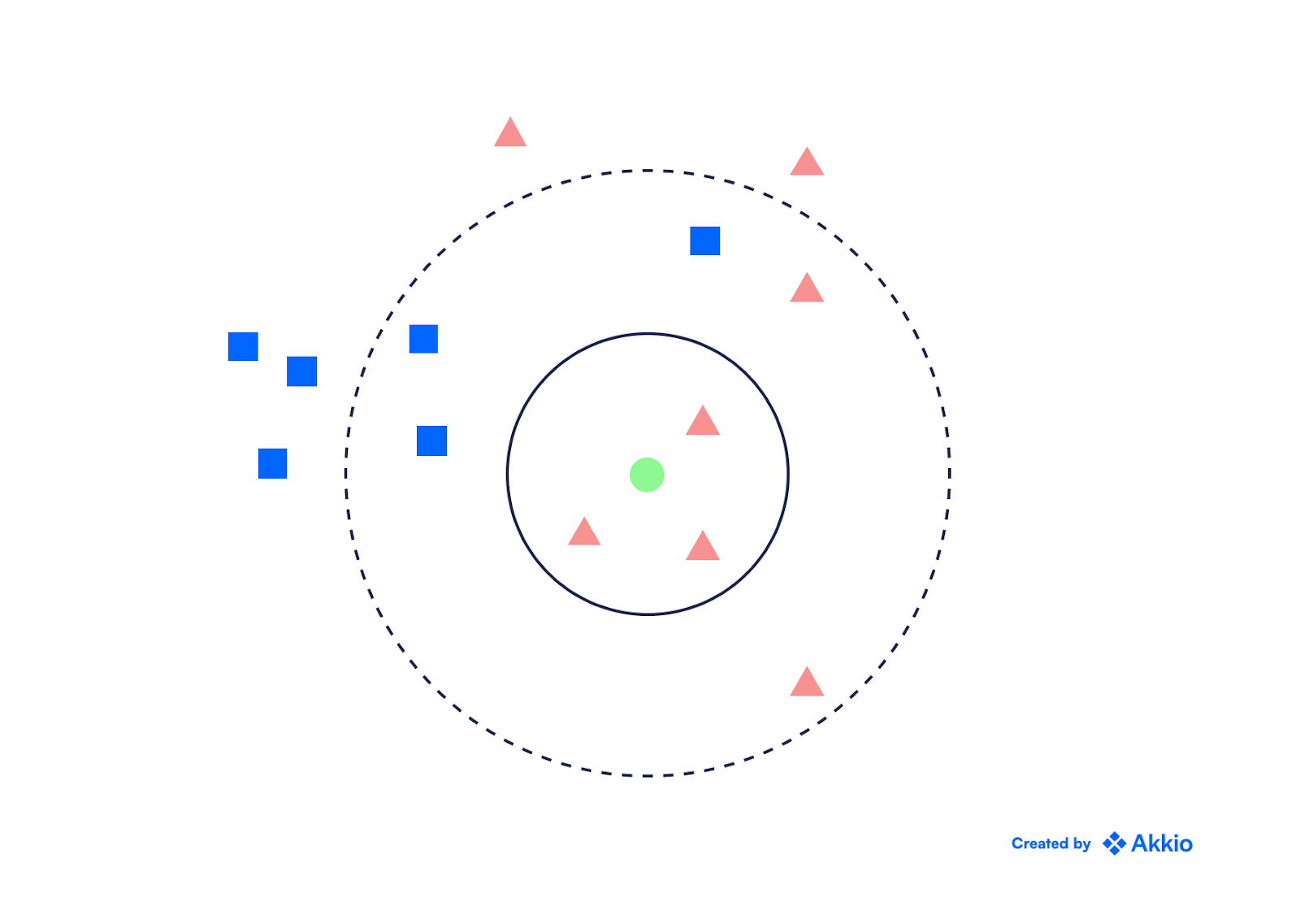
This is useful for two reasons:
It's easy to implement because we can just take the mean of each class, which is easy to calculate. KNN can also be used to solve classification problems with multiple classes, since it's not sensitive to the number of attributes that can be used.
Decision trees are a very common way to represent and visualize possible outcomes of a decision or an action based on probabilities. In a nutshell, a decision tree is a hierarchical representation of the outcome space where every node represents a choice or an action, with leaves representing states of the outcome.
Decision trees are highly human-readable since they generally follow a particular structure such as:
Now, we can visualize decision trees as a treelike structure where each leaf represents a state or an outcome, and the internal branches represent the various paths that could lead to that leaf. This is demonstrated in the following figure.

In our example above, consider whether or not the weather conditions are OK to play a football game. The first step would be to start at the root node labeled “Weather”, representing current weather conditions. We then move onto a branch, and the next nodes, depending on whether it’s sunny, overcast, or rainy. Finally, we continue down the decision tree until we have an outcome: could play or couldn’t play.
However, this simplicity is deceptive because decision trees can be used across a broad range of applications. For example, they are widely used in:
Decision trees are simpler than their random forest counterpart, which combines many decision trees into one model, which may be better suited for multi-class classification and other complex artificial intelligence tasks.
While decision trees and neural networks each represent a different way of classifying (or grouping) data into clusters that share common characteristics (or features), there are some key differences between them.
Essentially, decision trees work best for simple cases with few variables, while neural networks perform better when the data has more complex relationships between features or values (i.e., it’s “dense”).
As such, decision trees are often used as the first line classification method in simple data science projects. However, they may not scale well when faced with large amounts of high-dimensional data, i.e., it’s difficult to interpret meaningful results from their analysis.
Neural networks often become necessary if we seek to analyze large amounts of high-dimensional data, so let’s dive into neural nets.
Artificial Neural Networks have been one of the most commonly used machine learning algorithms. As the name suggests, they emulate biological neural networks in computers.
More complex models end up requiring more parameters which can be slower at classifying new data points compared to simpler methods such as linear or logistic regression algorithms. However, this flexibility and scalability mean they can handle large amounts of unlabeled data with ease.
The way ANNs work is by training a set of parameters on data. These parameters are then used to determine the model’s output, which may be an input or an action.
For example, if we have a model for predicting whether or not someone will buy a car based on previous purchases and demographics, we can give it new data to predict what’s next. We can use multiple inputs, including things like age, marital status, income, and so on to drive its predictions.
Nodes in a neural network are connected by weighted links based on their relevance to the outcome, which is typically discovered through an error-minimization method known as backpropagation. Each layer in the network, and its corresponding neurons, roughly correlate to certain features or attributes.
The simplest form of artificial neural networks is the perceptron. Nowadays, deep neural networks are used for more complex problems like image categorization, where there are countless possible inputs (e.g., different road conditions for a self-driving car).
The end goal of the training is to tune the parameters (weights) for each node so that they best represent the data it has seen. When all nodes are trained, they should be able to make decisions based on their parameters.
One drawback of ANNs is that they are very dependent on the data used to train them. If the data is not representative of what we’re trying to predict, it can lead to overfitting. Akkio mitigates these issues with regularization methods.
They also tend to be rather slow compared to other algorithms — especially when compared against the likes of linear regression — which may impact their performance when training large models. Akkio combats this with a proprietary model training process that's 100x faster than the competition. In other words, you can build an artificial neural network in seconds.
Another drawback is that neural networks can be difficult to explain to others who may not be as familiar with the field. That said, no other AI architecture has managed such an enormous amount of growth in such a short time.
Logistic regression is actually a non-linear extension of linear regression that allows us to handle classes. This is achieved by classifying predictions into a given class based on a probability threshold.
Consider the following example of the probability of passing an exam versus hours of studying. Suppose we have a variable Y representing the probability of passing an exam and a variable X representing hours spent studying. In that case, we can fit a line through these points using a regression predictor.

We may then classify the point into one of two categories: pass or fail, based on how close its line is to a threshold. While this is a simple example, logistic regression is used in many real-world situations, such as when determining creditworthiness along a spectrum of categories, as well as other multi-label classification problems.
Logistic regression is an alternative to the naive Bayes classifier, which uses Bayes’ theorem, and results in higher bias but lower variance.
Naive Bayes classifiers are a subset of linear classifiers where the assumption is that the value of a particular feature is independent of the value of any other feature.
This means that we can use Bayes’ theorem to calculate the probability of a particular label given our data by just looking at each feature individually, without considering how features may interact with each other.
Naive Bayes classifiers are often used in text classification because it’s easy to calculate probabilities from frequencies, and text typically has a large number of features (e.g., individual tokens in words).
They are also popular in spam detection because they can deal with the high dimensionality of email data (e.g., all the different words used in an email) without overfitting the data.
Linear Discriminant Analysis (LDA) is a classification algorithm that projects your data onto a linear decision boundary, which separates your training data into different classes.
It does this by finding the optimal hyperplane that maximizes the distance between different classes while minimizing the within-class variance. This is useful for multi-class classification problems where we want to group our data into different classes based on some shared characteristics.
Quadratic Discriminant Analysis (QDA) is a variant of LDA that allows for non-linear seperation of data. This is achieved by fitting a quadratic curve to your data instead of a linear boundary.
QDA is more computationally expensive because it has to compute the within-class variance for each class, which is a quadratic operation.
However, QDA may be a better choice than LDA if you have a lot of training data and you believe that the classes in your data are not linearly separable.
Akkio is the easiest no-code way to get started with classification in machine learning. With our drag-and-drop visual interface, you can build your first AI app in minutes on the cloud - no coding skills required. Once you build your first model, you can easily scale and deploy it in any setting, from the most complex production environments to embedded devices.
In short, Akkio makes AI accessible to everyone.
Traditionally, businesses that wanted to deploy machine learning models, from simple linear models to complex deep learning, needed to hire technical data scientists. This is because building AI infrastructure and models required specialized expertise with tools like Python and scikit-learn, as well as skills in big data, measuring errors with test data, Receiver Operating Characteristic (ROC curves), AUC, and more.
With Akkio, anyone can quickly and easily see model performance, including false positives versus true positives, precision and recall, and other metrics based on cross-validation. No more manually building a confusion matrix or creating a subset of your data—all of that is performed automatically.
To recap, machine learning classification is one of the most fundamental predictive modeling use-cases. It involves training learners to recognize patterns in samples so that it can assign new data items to an output variable.
The most common classification algorithms are support vector machines, tree-based models (such as decision trees), KNN models, artificial neural networks, and logistic regression models.
To use these models yourself, sign up for a free Akkio account or get started with our applications page for a simple tutorial. If you have any questions along the way, we’re always here to help.